For the past few years, researchers accessing the electronic medical records system have been most devoted to very basic forms of observation, surveillance, monitoring, and reporting. GIS has been theoretically applied for the most part, or to experiment with this analytic process, to supplement processes already underway for quality improvement activities, and/or to use GIS to produce basic spatial expressions of the data researchers are working with. The best use of GIS is to apply it to explain why certain things happen, for predictive modeling, and to evaluate change at some fairly sophisticated, detailed level of analysis. Yet for the most part, we primarily envision and apply GIS in health research to explain something that happened, not why and where it will happen.
The public health and quality improvement practices have already developed GIS in order to monitor and report upon such basic public health data as STD rates, or watching for infectious disease outbreaks, or monitoring the HIV incidence for suspicious sub-populations that serve as some nidus for some outbreaks. Public health and population health management programs employ it for reporting and planning purposes, such as for evaluating and recording childhood immunizations and to intervene where changes are most needed, or to study 18 to 24 year old Chlamydia rates in young people who are sexually active and demonstrate high rates for unexpected pregnancies.
Health improvement programs may use GIS to report on annual diabetes well visit rates or to show spatial relationships that might exist for high and low A1c, LDL and BP areas. In the background, some parts of the New York City GIS teams have been able to provide potential researchers with helpful baseline spatial data to use for developing new spatial surveillance systems, by providing important supporting spatial datasets for this work., such as relating the placement of clinics, offices or similar service facilities, to increase the engagement of patients with these programs.
A number of years ago, I graded the level of accomplishment an program had in spatial epidemiology applications as typically as high as level 5.5 to 5.75. This was based upon the different practices these groups normally engage in with GIS, using it to record, develop a history of, experiment with, and research how to implement this form of practice for basic health and safety concerns. This also has attached to it the supposition that for the most part, health care programs engage GIS at only some basic level. To determine just how much a program is engaged in the use of this tool, one need only reflect on how many measurable factors or details contained within an EMR system are being analyzed. Is the EMR being used to its fullest extent?
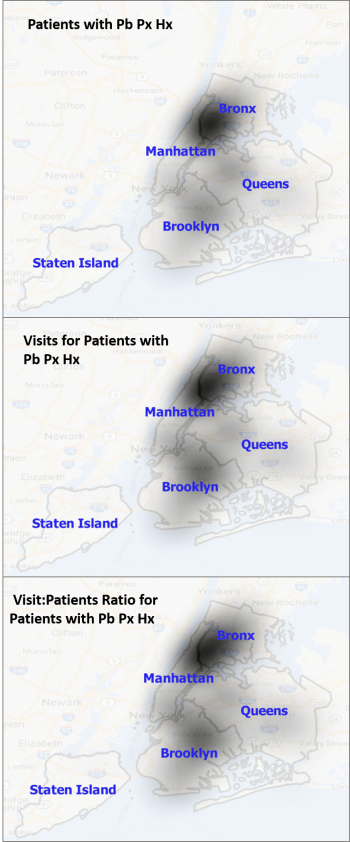
An example of the 3D Mapping of cases using SAS 8.* and 9.* (non-SAS-GIS), applied for surveillance purposes since 2007
For the most part, GIS in health has been very slow in advancing in the actual implementation of this means for reporting during the past ten years. We are certainly more familiar with the potential uses of GIS and its possible applications outside the already well-established realms define by environmental health, public health, population health, and quality of service/intervention teams. For the most part, these projects remain single examples of what is being done. Very few programs engage GIS at the level of big data reporting, such as mapping all 999 ICD9s at the spatial-temporal-age-gender-race level, per program, per facility, per larger unit (i.e. insurance programs, companies, NIH funded, SES focused programs) responsible for providing that care.
That is now changing within the population health surveillance and research activities I engage in on a regular basis.
For the past 2+ years, time was spent exploring the complexity of a complete EMR.
When we all first learn about ‘big data’ what we see as examples do not accurately demonstrate the details, length and complexity of health data that resides in the most basic, first or second generation residing within an EMR system. There are not just 1, 2 or 3, or even 4 to 6 special tables within which all data are recorded. Each group of data that can be placed within an EMR forms its own table, with multiple rows entered per unit of activity or metric being evaluated. These multiple row tables are modified or reconstructed into one-to-one or one-to-a-few formats.
When all patient data are entered, for example, these data which are stored initially as rows, get converted to columns, with patient identifiers (or its numeric assignment) as the index column(s) for this work. Each patient can then have columns that depict name, gender, dob, dod, mother’s name, address, state, zipcode, race, religion, insurer(s), etc. In the system I use, these tables are called dimensions and provide the most important personal, family and demographic data that exist for any given patient.
When a patient interacts with the health care system, there visits happen. Some programs call these interactions between health care staff, and another entity involved with the patient –such as patient, parent, other provider, previous care giver, other facility. In this review, I term these actions “visits”, but it has other common names elsewhere in the QOC/QI system.
This second dimension of care, the Visits, have only a few basic elements that define them, such as location (coded even down to the extreme, such as bed in a room), date, time (at day-hour-minute-second level) that something starts, ends or happens, time of closure or completion, etc. The study of the Visits Dimension for a patient’s care process provides the dimensions needed to correlate events over space and time, allowing for a review of practitioner or systems logic, and identifying situations where changes may need to be made, through rule-setting, policy, procedure, assignment of place for the event to happen, implementation of different programs for poor performance teams, groups or places. Without even looking at what practices were performed for a patient in the health care setting, we can see where further investigation may need to be made due to higher failures or death rates are seen for a given program. The details of what were done and which of these went wrong haven’t even payed a role yet in the health care process.
The third level or dimension of care pertains to the details of what events ensue during a given visit. The definition of each step in the care process also enables a time element to be defined for the care process. This means the patient may come in a time1, see the MD at time2, received an injection at time3, be seen by a specialist at time4, undergo and MRI at time5, be evaluated at time7, be admitted for inpatient care at time8, and then undergo nearly a thousand more time-defined processes over the next few days of treatment, recovery, and then discharge. Other temporal processes that can be evaluated here include time till initiation, overall time elapsed, time to recovery, and even post-inpatient time in relation to unwanted readmission events.
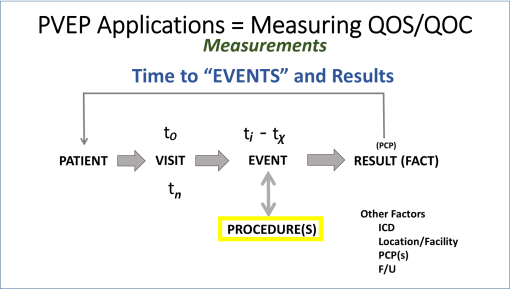
FIGURE 1
In this review of the care processes, what happens with a “visit” are generally interpreted as events or procedures. Events are what happens to a person, that typically is considered part of the care process. Procedures are practice related events that typically involved additional skills and are often coded with a procedure identifier because that identifier may be linked to the cost of care and billing. As a general rule, events are not charges, procedures are. Events carried out by a clinician are considered in defining the bill for the visit. Procedures carried out by the clinicians and/or technicians are often charged per routine, not per visit. But like always, we have exceptions–such as procedures that are free but documented as part of the visit. One of the most common of these within the system I operate are the Vital Signs taken and related medicate history questions asked and entered during each visit event.
The value of Procedures and Events coding is that the kinds of services being offered are considered, along with their relation to the overall timing and sequence of activities engaged in for the care process.
The “bread and butter” of all health care processes are the results of these procedures (and sometimes events). “Results” is the term applied to these datum elements here. And results are typically more than just the “result” of a test.
Typical results entered into a data warehouse include such datum as (with semicolons as separators): Yes; T; 1; 20; 3.45; “2,4,5,3,6,1,8” ; Complete; French; 13450; John Smith Sr.; “>150”; “168/96”; phq9; “above normal range”; Dr. Chase”; etc.
Over the past few years, extensive reviews were carried out for the size and numerica relationships between these four core “dimensional” datasets–patient. visit, event/procedure, and results–a general accounting of these figures, for just one visit and its linked events, is about 1:7-10:40-400:4000-40,000. I term this ration P;V;E or P; R.
Patients are their own unique number, Visits are their own unique number, but for a health related happening (a diagnosis linked to the visits), one patient may have 7-10 visits per year related to it (directly or indirectly) per year. Each visit in turn results in various events and procedures (vitals taken, labs ordered, educational materials provided, referrals give, etc.); even the most basic, simplest visit, such as a 9 month old well visits, will have Procedures entered for several immunizations, several health and safety checks with the mom, height and weight measures, pulse, an overall health evaluation visual exam of the kid done for scoring the child’s development, etc. etc. Therefore, 40 to 400 events (educating the mother about breast feeding) and procedures (labs, health metrics) are not atypical to any system.
The key to understanding each program, each system, requires a complete evaluation of these different measurables, numerically and percent wise, to see what the norm is for the system, and to see how its various subcomponents perform and document the same duties. So, for a single institution, we might assumed that all follow a protocol, and that each one could have different time related findings, but all within institutional standards, such that all of the products of that type of visit are the same (i.e. vitals documented and entered, immunizations that are due were completed, all of this occurring in less than one hour.
“Results” is the next dimension, but the data content of this is actually best considered multidimensional. The basic format of results data should be qualitative or quantitative, structured or non-structured, parametric or non-parametic. Different institutions may store subparts of these data into separate places, such as grouping all pulses into one dataset, or all lab measures and results into a single laboratory results file, or all xrays taken into a single xrays database, with dates, times, procedure taken, amount of energy administered, time in and time out, results, initial interpretation, final interpretation, etc.
Results are any outcome of happening linked to a procedure or sometimes event. Therefore, results can also be evaluated as relating to any of several groups of data entries:
- process or procedure related info, such as exposure time, amount of xray administered, test tube/sample number, type of test, numeric sequence of sample taken, frequency, drug administered Y/N, type of test administered, units of measurement, US or metric values,
- true results, like positive diagnosis (structured or non-structured), amount of energy read, size of nodule noted, amount of radioactive substance detected within tissue, estimated cells per cc, percentile ranking of height, LDL, BP, and id number for organism identified
- events, activities, notes, that follow and/or relate to those results , such as normal range, maximum range allowed, viewed by PCP #, diagnosed approved by department head (Y/N), reliability of results (0/1), event closed or not (0/1).
- general or non-specific non-structural data, such as words, text, impressions, notes of normal range, etc. entered as free text into a cell designed for this (Comment, Other, or Note cell ) and used by the practitioner to provided additional notes, which may or may not be specifically related to the procedure at hand.
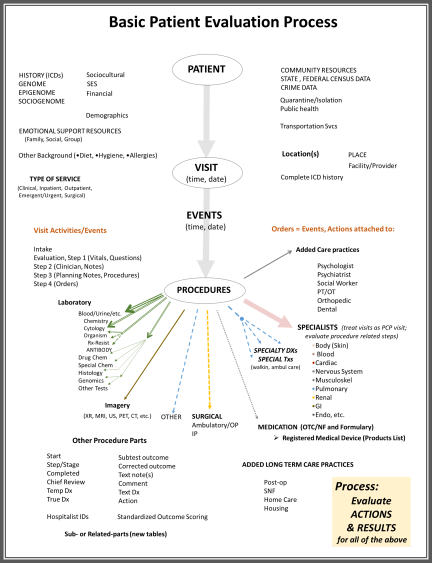
FIGURE 2
The data evaluation, up to this point, focuses on just the Visit as the chief event, or research and analysis unit. We can look at one visit and all that happens in relation to it, be it a well visit, an inpatient stay, an emergency event followed by hospitalization, a referral to a specialist, a meeting with a social worker. You can analyze the time component, the sequence, and/or the length of time until a certain point is reached (how long until the MRI was done?).
The data evaluation can also assess all of these events, over time, for a single patient, in relation to his/her medical history, and onset of new diagnoses or ICDs.
In the following model, the sequential visits related to single problems are assessed, such as diagnosis of heart disease, leading up to valve replacement. Each one of the processes as defined in Figure 1 above, is presented by an oval in this figure.
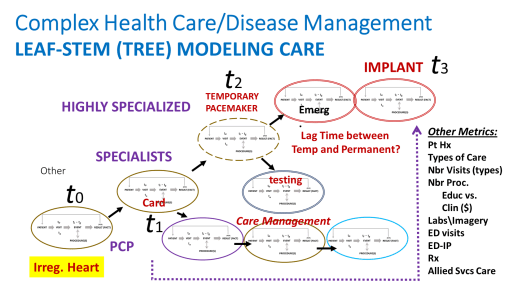
FIGURE 3
Over time, these processes of care escalate and can have a cascading effect on patient health care needs.
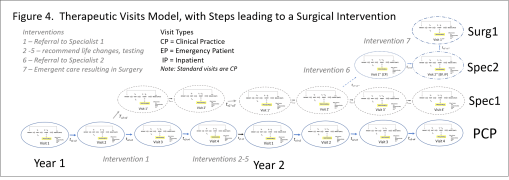
FIGURE 4
In the more complex, lifespan models, all of the diagnoses and actions taken to care for someone may be placed into this model, to define lifelong related population health processes and individual health care experiences.
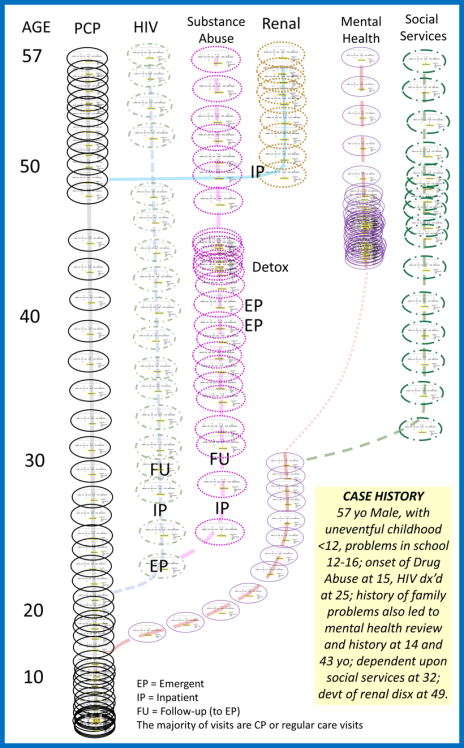
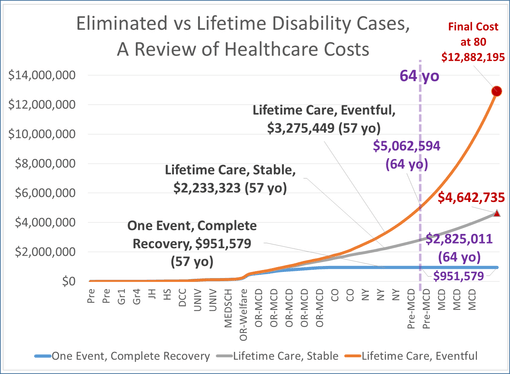
In an application of this model to a personal medical history model, to review cost of care to the overall results of that care, for someone with a long history of epilepsy, the following cost analyses models were developed. They predict the relationships of rising costs for care in patients well controlled, not controlled, and those who underwent some intervention care (such as neurosurgery), versus those who didn’t. [These were all covered earlier; the arguments for costs depicted here are found on those blog pages].
The Spatial Modelling Dimension
The next level of implementing this process for evaluating health care involved the application of these above statistical processes to data that may be linked to GIS research processes.
All data in an EMR, structured or not, parametric or not, numeric or text, can be converted to fully quantitative data by adding simple several spatial elements to the project.
The common comparisons between facilities and clinics, or health care between races and neighborhoods, for examples, are informally spatial in nature, and more formally best referred to as geographic, since latitude and longitude, distances, time, and spatial relationships are not a part of their formal numbers based evaluation processes. By add the location-distance relationship, such as through the use of centroids, or space area analyses, or patient place (lat long) data, any and all health EMR data becomes quantitative in nature. A fully text based, non-structured, content analysis, or 50 people undergoing a rare experience, is made spatial by adding lat-long to their analyses (although this one metric alone benefits more by other non-parametrics such as race, gender and age).
Health care analyses that become replicable and semi- to fully-automated in EMRs analyses can also be semi-automated or manually interpreted using GIS. The values of this application for GIS to healthcare monitoring are fairly easy to visualize.
By implementing a GIS at this time for this surveillance program, a second process for evaluating health spatially is now in operation.*
This process of spatially evaluating data in SAS was developed a few years ago. The means for producing videos of these 3D models of health in an urban area were perfected, in SAS Basic and SAS Graph (no SAS GIS was developed).


Which is fortunate, since SAS GIS has recently been turned over to a new workstation format for spatial analysis using SAS–SAS Enterprise with ERSI ArcGIS extension. At the institutional level, this doubles the cost for implementing such a program at the QI/QOC level for Managed Care programs, like the ones I have worked with.
The spatial SAS methods applied serve in the analysis and projection/display process, with the animation of results that can be developed for rotating 3D model imagery the major benefit of this spatial analysis method. [see Below] We can further improve upon this by smoothening out the shapefile centroid data used to produce these models, by converting irregular shapefile (zip code) data into more regular square cell grid data (the algorithms for this I presented numerous times elsewhere). We can further smoothen these presentations with a hexgrid modeling algorithm I developed (also detailed elsewhere; no example here, for now).
With the addition of a regular GIS workstation to the analytics process for evaluating 20 years of 11 million people’s health data, this work environment enables higher levels of the above (see initial figure) scoring system to be reached–Levels 6 and then Level 7. Because the data pulls and reconfiguration are based upon automated or semiautomated, often SQL and then SAS macro processes, it is possible to run these evaluations for numerous new types of studies: for example, re-evaluating past reserch projects and questions across the system, by focusing on any form or group of ICD, labs, diagnostics, psych test results, demographical, Age-SES-Race-Ethnicity-Religion (SAS-RER) grouping, neighborhood (latlong), NYC healthy area polygon, nearest office visit (location theory/distance), inpatient stay pattern, Log reg / Kaplan Meier derived life expectancy patterns.
The following is an early example: